Document parsing that
actually works
on real documents.
Scanned pages, complex tables, embedded charts, mathematical formulas — the documents that break other tools. IntraParse handles them all, delivering structured results in seconds.
Most document parsers fail
when documents get real.
Enterprise documents aren't clean. They're scanned copies, dense technical reports, financial filings with nested tables. Existing tools either choke on complexity or skip pages entirely.
Same document. Same task. Different results.
2x faster. Every table, figure, and formula preserved. Also available for on-prem deployment.
Every element. Nothing skipped.
Real output from a 116-page scanned NASA technical document. Tables, figures, formulas, text — each extracted and structured.
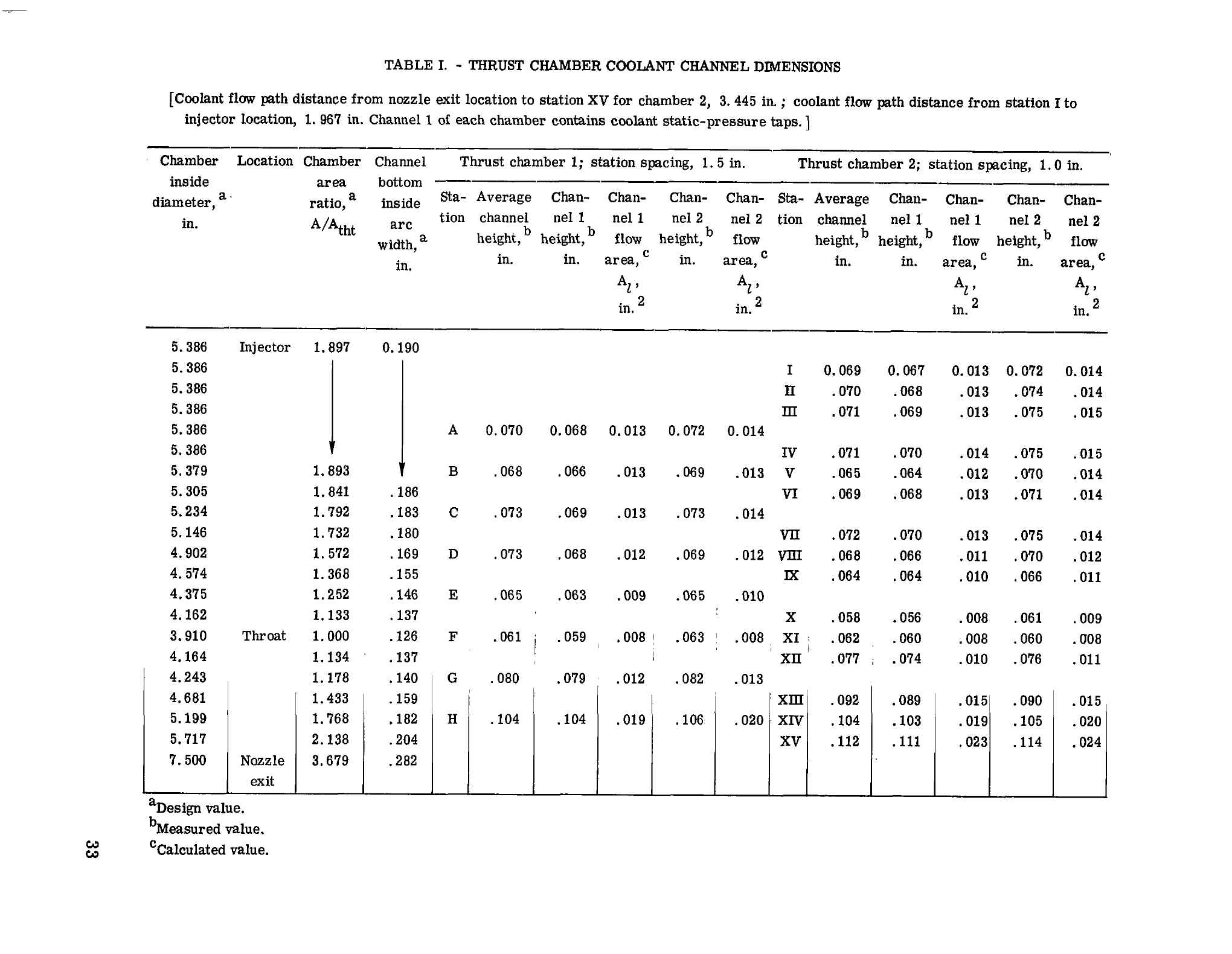
Table I — Thrust Chamber Coolant Channel Dimensions
| Dia. | Loc. | A/Aₜₕₜ | Arc W. | Chamber 1 (1.5 in.) | Chamber 2 (1.0 in.) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Stn | Avg H. | Ch1 H. | Ch1 A | Ch2 H. | Ch2 A | Stn | Avg H. | Ch1 H. | Ch1 A | Ch2 H. | Ch2 A | ||||
| 5.386 | Inj. | 1.897 | 0.190 | I | 0.069 | 0.067 | 0.013 | 0.072 | 0.014 | ||||||
| 5.386 | II | .070 | .068 | .013 | .074 | .014 | |||||||||
| 5.386 | III | .071 | .069 | .013 | .075 | .015 | |||||||||
| 5.386 | A | 0.070 | 0.068 | 0.013 | 0.072 | 0.014 | |||||||||
| 5.386 | IV | .071 | .070 | .014 | .075 | .015 | |||||||||
| 5.379 | 1.893 | B | .068 | .066 | .013 | .069 | .013 | V | .065 | .064 | .012 | .070 | .014 | ||
| 5.305 | 1.841 | .186 | VI | .069 | .068 | .013 | .071 | .014 | |||||||
| 5.234 | 1.792 | .183 | C | .073 | .069 | .013 | .073 | .014 | |||||||
| 5.146 | 1.732 | .180 | VII | .072 | .070 | .013 | .075 | .014 | |||||||
| 4.902 | 1.572 | .169 | D | .073 | .068 | .012 | .069 | .012 | VIII | .068 | .066 | .011 | .070 | .012 | |
| 4.574 | 1.368 | .155 | IX | .064 | .064 | .010 | .066 | .011 | |||||||
| 4.375 | 1.252 | .146 | E | .065 | .063 | .009 | .065 | .010 | |||||||
| 4.162 | 1.133 | .137 | X | .058 | .056 | .008 | .061 | .009 | |||||||
| 3.910 | Thr. | 1.000 | .126 | F | .061 | .059 | .008 | .063 | .008 | XI | .062 | .060 | .008 | .060 | .008 |
| 4.164 | 1.134 | .137 | XII | .077 | .074 | .010 | .076 | .011 | |||||||
| 4.243 | 1.178 | .140 | G | .080 | .079 | .012 | .082 | .013 | |||||||
| 4.681 | 1.433 | .159 | XIII | .092 | .089 | .015 | .090 | .015 | |||||||
| 5.199 | 1.768 | .182 | H | .104 | .104 | .019 | .106 | .020 | XIV | .104 | .103 | .019 | .105 | .020 | |
| 5.717 | 2.138 | .204 | XV | .112 | .111 | .023 | .114 | .024 | |||||||
| 7.500 | Noz. | 3.679 | .282 | ||||||||||||
20 rows · 16 columns · Multi-row spans preserved · Footnotes: a = Design value, b = Measured, c = Calculated
Seconds, not minutes. Every page, not some.
69 pages
in 59 seconds
Scanned NASA document
180+
pages per minute
Sustained throughput
10,000+
documents tested
Production-ready
GPU-accelerated on NVIDIA H100 infrastructure. Your document starts processing immediately — no queue, no wait.
Upload. Process. Done.
Upload your document
Drag and drop a PDF through the web interface, or send it via the API. Scanned or digital. Up to 50 MB.
GPU pipeline processes every page
Every page is analyzed visually, not just OCR'd. Tables stay structurally accurate. Figures get detailed descriptions. Formulas become clean LaTeX. Nothing skipped.
Get structured results
Clean JSON with every element in reading order. View in the browser with side-by-side PDF comparison, download it, or consume via API.
One endpoint. Structured data back.
Get your API key from the dashboard. Send a PDF. Receive structured JSON. That's the entire integration.
curl -X POST https://intraparse-api.intraplex.ai/api/v1/parse \ -H "Authorization: Bearer ip_live_..." \ -F "file=@quarterly-report.pdf"
{ "document_id": "d7f2a1b3-...", "filename": "quarterly-report.pdf", "page_count": 24, "chunk_count": 87, "chunks": [ { "type": "text", "text": "Executive Summary...", "page_no": 1 }, { "type": "table", "text": "| Metric | Q3 | Q4 |...", "page_no": 5 } ] }
See it on your own documents.
IntraParse is in beta and free to use. 50 pages per day. No credit card. Upload a document and see the difference in seconds.
Start Parsing